Регистрация на РИФ.Иннополис и OS DAY
Зарегистрироваться
Александр Коротков, генеральный директор компании Postgres Professional Development, один из трех ведущих российских разработчиков (major contributor) PostgreSQL.
В 2008 г. окончил МИФИ с красным дипломом. В 2012 г. защитил кандидатскую диссертацию, основанную на разработках для СУБД PostgreSQL. Занимался разработкой таких веб-проектов, как онлайн сервис анализа ДНК «Мой Ген» и портал Государственной Думы. Разработчик PostgreSQL с 2010 года. Среди разработанных Александром возможностей PostgreSQL можно выделить: расширяемость индексных методов доступа (команда CREATE ACCESS METHOD, generic WAL), усовершенствование буферного менеждера, позволившее обрабатывать более миллиона запросов в секунду, улучшения GiST (split, buffering index build), улучшения GIN (posting list compression, fast scan), индексирование JSON, индексный поиск по регулярным выражениям, статистика для массивов и диапазонных типов и многое другое.
PostgreSQL – одна из самых “всеядных” СУБД в мире. Данная СУБД поддерживает множество аппаратных платформ, среди которых: x86, x86_64, IA64, PowerPC, PowerPC 64, S/390, S/390x, Sparc, Sparc 64, ARM, MIPS, MIPSEL, M68K, PA-RISC; а также операционных систем, среди которых: Linux, Windows, FreeBSD, OpenBSD, NetBSD, OS X, AIX, HP/UX, Solaris, UnixWare. Этим обсусловлено то, что в коде PostgreSQL используются наиболее универсальные решения, которые подходят для всех поддерживаемых операционных систем и аппаратных платформ.
Сервер СУБД PostgreSQL, представлен в операционной системе в виде множества процессов: postmaster, принимающий соединения от клиентов; backend’ы, обслуживающие отдельные клиентский соединения; а также checkpointer, backround writer и другие служебные процессы. PostgreSQL не использует треды, за что длительное время подвергался критике, но сейчас становится понятно, что мультипроцессная модель оправдывает себя. На сегодняшний день мультипроцессная модель широко применяется даже за пределами серверных приложений. Так, например, веб-браузер Chrome использует мультипроцессную модель, а Firefox на неё переходит.
Упрощённая схема взаимодействия процессов PostgreSQL представлена на рисунке 1. Основным способом взаимодействия процессов является разделяемая память. Для того, чтобы такое взаимодействие могло осуществляться корректно, используются различные способы синхронизации, в первую очередь – блокировки.

Рис 1. Упрощённая схема взаимодействия процессов PostgreSQL через разделяемую память
В PostgreSQL реализовано несколько типов блокировок, каждый из которых решает свои задачи.
Помимо вышеперечисленных типов блокировок, в PostgreSQL присутствуют row-level locks, predicate locks, advisory locks и другие, которые, в свою очередь, реализованы с использованием перечисленных выше трёх базовых типов блокировок.
В процессе оптимизации PostgreSQL под современные многоядерные сервера Intel и Power8, мы обнаружили, что использование spinlock является узким местом в менеджере буферов. Решением этой проблемы стала замена spinlock’а на атомарные операции с переменной состояния, аналогично тому как это было сделано для LWLock’ов в PostgreSQL 9.5. Совместно с ведущим разработчиком PostgreSQL Андресом Фройндом (Andres Freund), мы разработали патч, благодаря которому функция PinBuffer стала выполнять операцию Compare and Swap (CAS) в цикле, а функция UnpinBuffer – атомарный декремент. Данный патч был принят в PostgreSQL 9.6. Благодаря нему удалось достигнуть более 1 миллиона запросов в секунду на многоядерном сервере Intel (Рис 2). Дополнительно, с помощью выравнивания структур данных по cacheline’ам удалось достигнуть около 1 722 000 запросов в секунду. Однако выравнивание структур данных было предложено уже после feature freeze PostgreSQL 9.6, и поэтому будет рассматриваться для следующего major релиза.
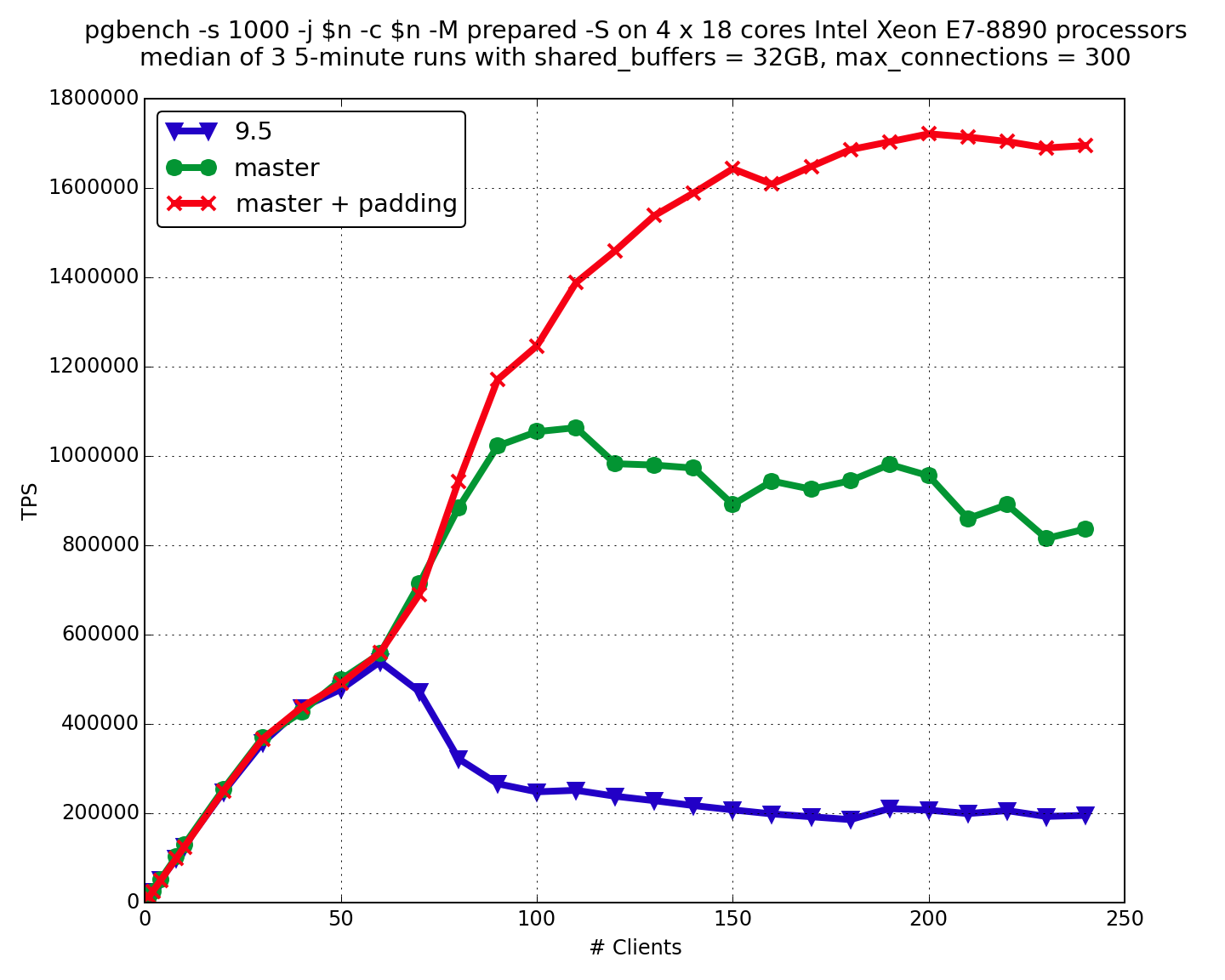
Рис 2. Сравнение производительности PostgreSQL 9.6 на 72 ядерном сервере Intel
На многоядерном сервере Power8 оптимизация для Pin/UnpinBuffer также дала эффект (Рис. 3).
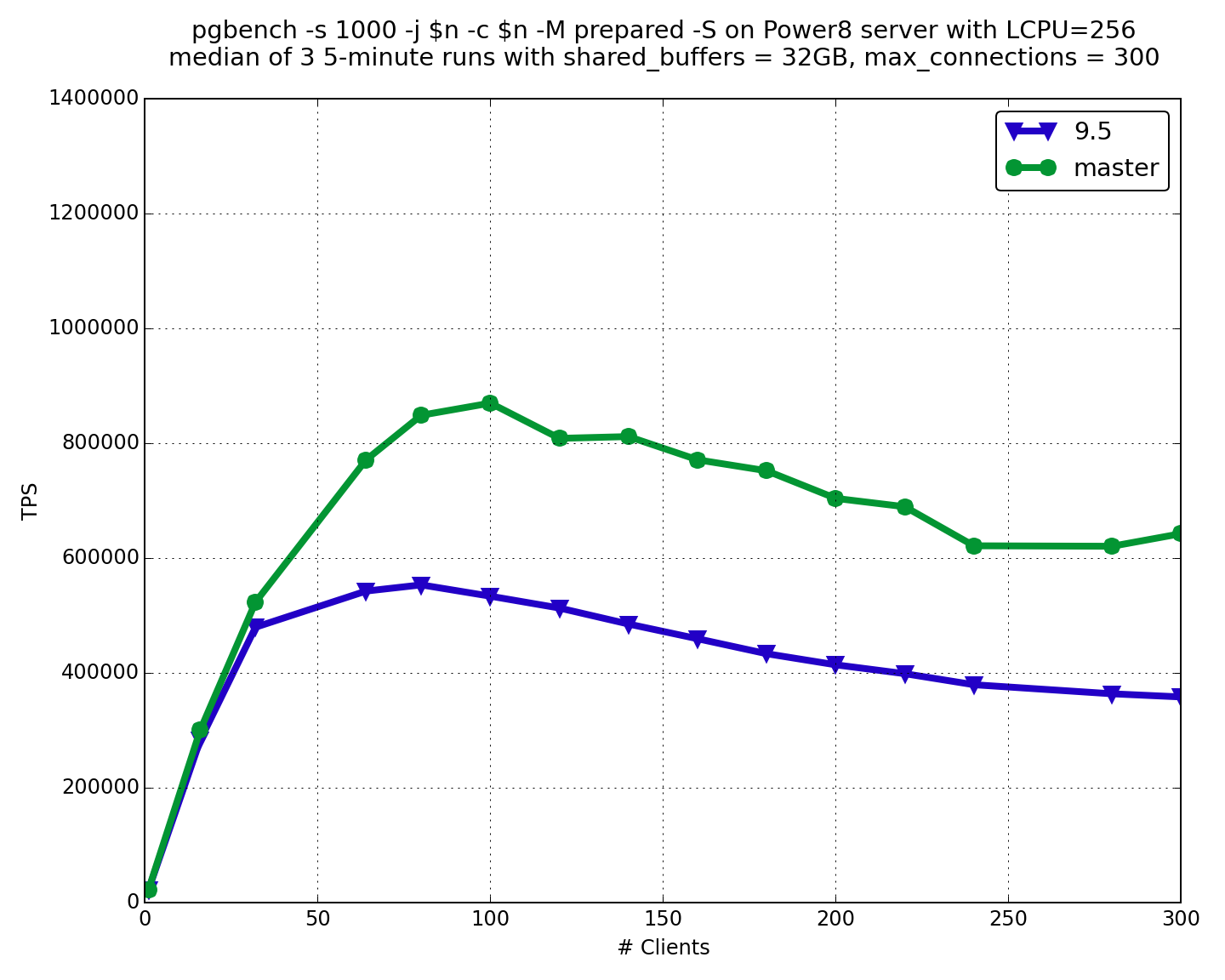
Рис 4. Сравнение производительности PostgreSQL 9.6 на 72 ядерном сервере Power8
Однако, в ходе дальнейшего тестирования мы обнаружили, что очень много времени тратится на взятие LWLock’ов. Как известно, начиная с PostgreSQL 9.5 взятие LWLock’а преставляет собой цикл CAS операций. Если посмотреть на ассемблерную реализацию операции CAS под Power8, то можно увидеть, что она представляет собой цикл (Листинг. 1). Таким образом, выполнение операции CAS в цикле – это цикл в цикле. При большой конкуренции за изменение значения, это может быть заметно медленнее, чем выполнение одинарного цикла.
Листинг 1. Исходный текст операции CAS на ассембере для Power8
# Входные параметры:
# r3 – старое значение, r4 – новое значение
# r5 – адрес атомарной переменной
# Выходные параметры:
# r6 - результат (1 - успех, 0 - неудача)
# r9 - результирующее значение переменной
li6,0
.L1: lwarx9,0,5
cmpw0,9,3
bne-0,.L2
stwcx. 4,0,5
bne-0,.L1
li6,1
mr9,5
.L2: isync
Очевидно, что между командами lwarx и stwcx могут располагаться и более сложные вычисления. Используя это, мы реализовали критичную по производительности функцию попытки взятия LWLock’а LWLockAttemptLock с помощью ассемблерной вставки. Как видно на рисунке 4, благодаря этой оптимизации удалось достигнуть более 1 200 000 запросов в секунду. Минусом данного подхода является то, что мы выходим за уровень абстракции в виде атомарных операций, который предоставляет нам компилятор. В целесообразности подобных оптимизаций сложно убедить сообщество PostgreSQL, однако данная оптимизация была включена в ветку Postgres Professional.
Листинг 2. Исходный текст функции LWLockAttemptLock, оптимизированной на ассембере для Power8
# Входные параметры:
# r3 – битовая маска, r4 – инкремент
# r5 – адрес атомарной переменной
# Выходные параметры:
# r6 - результат (1 - успех, 0 - неудача)
.L0: lwarx9,0,5
and8,9,3
cmpwi8,0
bne-0,.L1
add9,9,4
stwcx.9,0,5
bne-0,.L0
li6,0
b0,.L2
.L1: li6,1
.L2: isync
.png)
Рис 4. Сравнение производительности PostgreSQL 9.6 с ассемблерной оптимизацией LWLockAttemptLock на 72 ядерном сервере Power8
Таким образом, на примере PostgreSQL, мы можем видеть, что реляционные СУБД, для которых традиционно узким местом считалась дисковая подсистема, сегодня в зависимости от данных и нагрузки могут критическим образом зависеть от способа синхронизации потоков выполнения. Несмотря на свою “всеядность”, PostgreSQL успешно оптимизируется под современные многоядерные архитектуры благодаря удачному выбору примитивов синхронизации, реализации которых разработаны под самые разные платформы. Компания Postgres Professional вносит свой вклад в оптимизацию PostgreSQL под современные многоядерные архитектуры и готова отказывать вендорскую поддержку высокопроизводительных решений, которые опережают развитие Open Source community версии.